“A deceptively simple question”: the tells of an AI-written lecture
Twelve machine-written economics lessons - on monetary policy, tax, mergers and growth - all open with the exact same four words. Listen through each example.
But after reviewing a few dozen by ear, I kept noticing the same opening move — the lesson would clear its throat and announce that we were about to
tackle “a deceptively simple question.” Tax policy? A deceptively simple question. Where money comes from? A deceptively simple question. Whether to break up a monopoly? … deceptively simple.
I pulled every generated transcript that uses the phrase. There are twelve of them, on twelve genuinely different topics, and they are identical in framing and phrasing. You can listen to them below.
Fig. 1 · Twelve lessons that open with “a deceptively simple question” · press play
AI writing has a fast-growing catalogue of these tells. Lately the attention is on the “It’s not X, it’s Y” construction — dissected in the Guardian and The Conversation — and as far back as 2024 people were pointing at the word “delve” as the giveaway. Wikipedia even keeps a running Signs of AI writing page. I wanted to know how my own generated scripts stacked up: the “deceptively simple question” was the obvious offender, but what else was hiding in there?
So I went through the whole corpus: 223 voiceover scripts (257,389 words) across two courses: 162 from Macroeconomics and 61 from an Industrial Organisation course, plus their rendered MP3s. I focused on document frequency: how many distinct transcripts contain a phrase, rather than how often it fires inside one lesson.
Through a mix of manual review and some regex, I pulled out a set of stock phrases and counted how many scripts used each. The most common were the ones I’d actually asked for in the prompt, or fed in as context: “energising takeaway,” “pivotal concept,” “why does this matter.” But plenty I never requested showed up just as reliably: the “imagine…” cold-opens, the “welcome to” warm-ups, and of course the deceptively simple question.
Fig. 2 · Where each stock phrase lands inside a script · 0 phrase groups · 223 AI-narrated lessons
start of script → the templated arc → end of script
Read it top to bottom and you’re reading the shape of a generated lesson. The openers pile up against the left edge (0 = first word): “welcome to”, “today we’re”, our “deceptively simple” framing and the vivid “imagine…” cold-opens all fire in the first breath. The structural beats sit in the middle — “pivotal concept” reliably around the one-third mark, numbered like worked exam answers (“that brings us to the second pivotal concept”). Some of this will be directly related to the source material, of course. And then there’s that wall of dots on the bottom row, jammed against the right-hand margin. Hit ▶ on any row with a button — “imagine”, “pivotal concept”, the closer — and use ‹ › to walk through the lessons one by one.
The closer I asked for
That bottom row is the strongest tic in the dataset, and the most sheepish one to report: it’s the “energising takeaway” instruction, obeyed. It sounds a bit awkward when listening back to every lesson now and if I were writing the prompt again I’d ask for something more natural, but the model doesn’t question it.
158 of the 223 scripts — 70.9% — end on those exact two words (the model oscillates between the British and American spelling, so I match both), at a median position of 0.905 — 90% of the way through every script. The only mildly interesting wrinkle is how literal the obedience is: the model lifts the prompt’s own adjective rather than paraphrasing it as “a thought to carry with you,” and it does so seven times in ten.
“Here’s the energising takeaway: once you fix what the government buys, only the spending path matters…” · “…I want you to walk away with this energising takeaway: market size is only the starting point…” · “Here’s the energising takeaway: models are not verdicts, they are lenses…”
The mid-script pivot behaves the same way: a “why does this matter” beat — straight out of “explain why they matter” — surfaces in 37% of scripts, reliably around the one-third mark. Open, pivot, close: the five-act shape people hear is the four sentences of the brief, surfaced as phrases.
What I built (and open-sourced)
All of this was part of Pelajari, a small content pipeline I’ve put on GitHub alongside this post. You author a course as Markdown/YAML; a Python notebook pipeline fetches the lecture transcripts, has GPT-5.1 write the structured summary and then the voiceover script, and renders the audio with ElevenLabs (falling back to OpenAI TTS at times when it was getting a bit too expensive). The artefacts are served through a Cloudflare Worker backed by R2 to two clients: a React Native Expo mobile app and the SvelteKit web preview below.

The second-stage prompt — the one that turns the summary into narration — is admittedly fairly naive:
Craft a voiceover script for a lesson. Use a confident, encouraging mentor tone with a bit of personality. Focus on helping learners truly grasp the key ideas, connect the dots, and feel motivated to explore further. Highlight two or three pivotal concepts, explain why they matter, and close with an energising takeaway. Write continuous narration (no bullet points or headings) and convert any LaTeX into plain English concentrating on ensuring the script is pronounceable.
Read that next to the arc and the “template” mostly resolves into two different things. Some of it is the prompt talking back to me almost verbatim: I asked for “two or three pivotal concepts,” to “explain why they matter,” and to “close with an energising takeaway,” and the model returns those exact words, in that order. Counting them up isn’t so much a discovery as a receipt.
The genuinely emergent tics are the ones the prompt never names — and they all hang off its vaguest instructions. “A bit of personality,” “confident, encouraging mentor tone,” “feel motivated to explore further”: none of that comes with any phrasing attached, so the model supplies its own, and it supplies the same phrasing every time. “A deceptively simple question” is what “a bit of personality” looks like at scale; the “imagine…” cold-opens and the “welcome to / today we’re” warm-ups are what “encouraging mentor” collapses into. Hand a model a vibe instead of words and it will quietly standardise the vibe.
Fig. 3 · Share of the 223 scripts using each phrase at least once
Most tics show near-identical coverage in both courses — the signature of the recipe, not the subject. A few are genuinely content-induced: flip to By course above and “pivotal concept” jumps to 70% in Industrial Organisation versus 49% in Macroeconomics, because IO lessons are more taxonomic and the model reaches for numbered structure more often.
Counter-intuitively I'd also sworn I kept hearing “cut through the fog.” But where “deceptively simple” recurs a dozen times, “cut through the fog” appears exactly once in the entire corpus. I got this wrong, which you may notice in the Python notebooks.
So how formulaic is it, really?
Before making too much of this, it’s one model, one pair of prompts, two courses — not a verdict on all “AI writing,” just an interesting personal case study with data meaningful to me. Document frequency is a blunt instrument, too: a chunk of what it surfaces are phrases I explicitly asked for, so finding them everywhere is closer to a receipt than a discovery. And the 1.4% figure below only counts the specific phrases I bothered to match, which stuck out and seemed relevant. Not every cliché is accounted for.
With that said, here’s the counterweight to the “it’s all template” reading. If you mark every character that falls inside a stock phrase and divide by the script length, the median script spends just 1.4% of its characters on clichés, topping out at 4.2%. The tics are structural: they cluster in the handful of structural slots (open, pivot, close) that carry the most rhetorical weight, which is exactly why they’re so audible despite being numerically tiny.
The end result audio, in part due to ElevenLabs’ engaging text-to-speech voice rendering, is actually pretty good. Very listenable. With context of what came before there may well be more variation, which the model did not have access to.
It helps to remember what the model is actually doing in those template slots. It’s inflating a 180-300 word summary into a script several times that length, and the words it adds to bridge the gap are mostly connective rhetoric.
The gulf of specification
There’s a name for what produced all this. In their forthcoming Evals for AI, Hamel Husain and Shreya Shankar describe the gulf of specification: the space between what a developer means and what they actually manage to write down. My naive prompt definitely falls into it. “A bit of personality” is an intention, not an instruction.
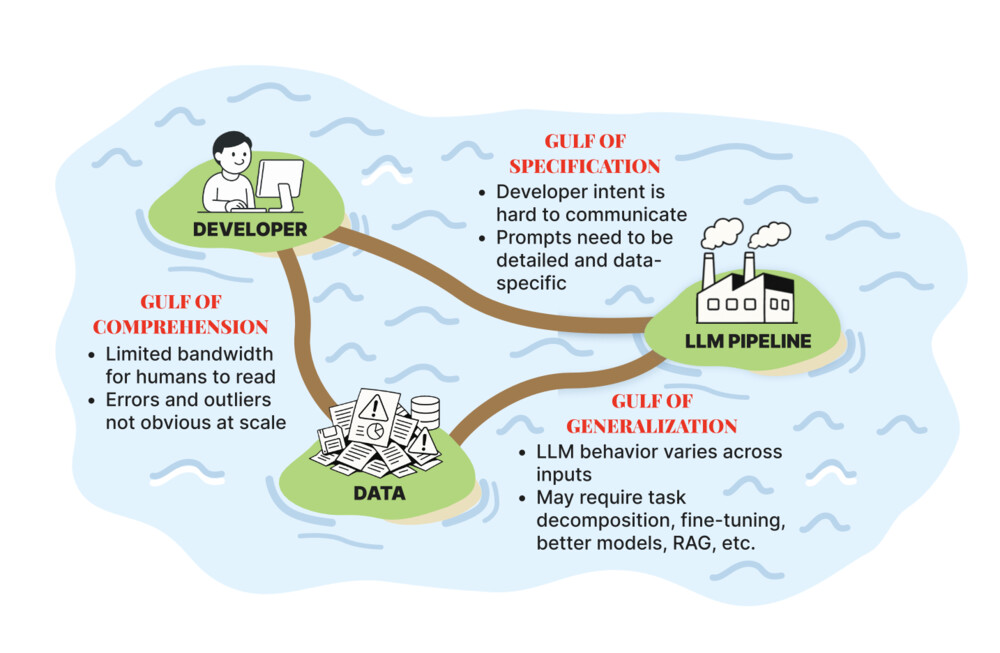
The view from “delve”
Everything above is phrasal — multi-word scaffolding in one prompt’s output. The tell that attracted global attention was a single word: “delve.” And unlike my hobby corpus, it’s now been measured at the scale of the published record. Matsui (2025) tracked 135 candidate AI-influenced terms across 27.5 million PubMed abstracts from 2000-2024; 103 of them rose meaningfully by 2024, and “delve” was the single biggest mover — the lonely red point stranded in the top-right of the chart below.

Noting that Matsui found these words began climbing around 2020 — before ChatGPT shipped in November 2022 — so the model amplified an existing drift rather than inventing it from scratch. (The paper also can’t resist the joke: its own title is “Delving Into PubMed Records.”) My “deceptively simple question” is the same phenomenon caught one rung lower down — not yet in the published record, just in one person’s render queue, but already perfectly, measurably on rails.
The view from a New Zealand ear
There’s a last thing the counting doesn’t capture, and it’s the thing I actually noticed first. To a New Zealand ear, the whole register is off. The relentless warmth, every lesson thrilled to see you, every dry result repackaged as an “energising takeaway”, lands somewhere between an American keynote and a children’s-TV host. Kiwi explanation tends to run more understated - “not too bad” is actually pretty high praise. So a voice this uniformly excited about contestable markets reads, to me, as faintly uncanny: fluent, friendly, and unmistakably performing.
Deceptively simple questions that turn out to be not-so-simple and not so-deceptive also seem to be a slightly manipulative way to frame these lessons. Ultimately pointing to more care needed in developing ed-tech applications using LLMs.
References
- Matsui K. Delving Into PubMed Records: How AI-Influenced Vocabulary has Transformed Medical Writing since ChatGPT. Perspectives on Medical Education. 2025;14(1):882–890. doi:10.5334/pme.1929 · PMID 41356414 · PMC12679996. Figure 1 reproduced under CC BY 4.0.
- Husain H, Shankar S. Evals for AI (forthcoming, O’Reilly). The Three Gulfs diagram originates in their Maven AI Evals course.
Reproducible end to end: the counting lives in 03_script_phrase_analysis.ipynb,
and scripts/tts-tics/build.py regenerates the data and cuts the audio clips
straight from the rendered MP3s with ffmpeg. To prepare clips for this blog post, each clip was sliced on exact word-level timestamps from Deepgram — every MP3 goes through its
transcription API, the stock phrase is matched against the returned word list, and the cut
lands on the first and last word's boundaries. So the openers and closers alike sit precisely
on the phrase, with no character-offset estimation and no stray breath to trim.
Code was written with the help of coding assistants (Codex and Claude); Claude also helped draft this post. The GitHub repo is available, but the source course material and the full derived summaries can't be shared.